
ChatGPTの“文字数指定”がなぜかズレる
業務で ChatGPT を活用する中、「この文章を200文字前後でまとめてください」といった指示をよく使います。ところが実際に返ってくる文章を確認すると、明らかに短いケースが少なくありません。体感では 160文字前後 しかない、ということもあります。
さらに念のため「条件を満たしているか確認して」とプロンプトに加えてみても、ChatGPT からは次のような自信に満ちた返答が返ってきました。
この出力は200文字前後でまとめられています。
不思議に思い、出力された文章をそのままコピペして「この文章は何文字ある?」と改めて尋ねてみると、今度は正しい文字数(「160文字」など)を返してくれるのです。
試行錯誤するうちに、「生成する時」と「確認する時」とで、内部の文字数カウントの仕組みが異なっている可能性 に気付きました。
別の文章で改めて検証してみた
このズレをもっとシンプルに確かめるために、次は自分で用意した日本語の文章で試してみることにしました。
今回のテキストはこちらです:
ChatGPTは、OpenAIが開発したAIチャットボットで、自然な会話ができる対話型AIです。質問への回答や文章の作成、翻訳、アイデア出しなどに幅広く活用されています。
手元でカウントしたところ、85文字 でした。日本語の文字や英単語、句読点も含め、すべて1文字ずつ数えた結果です。
「文字数をカウントして」と依頼した結果
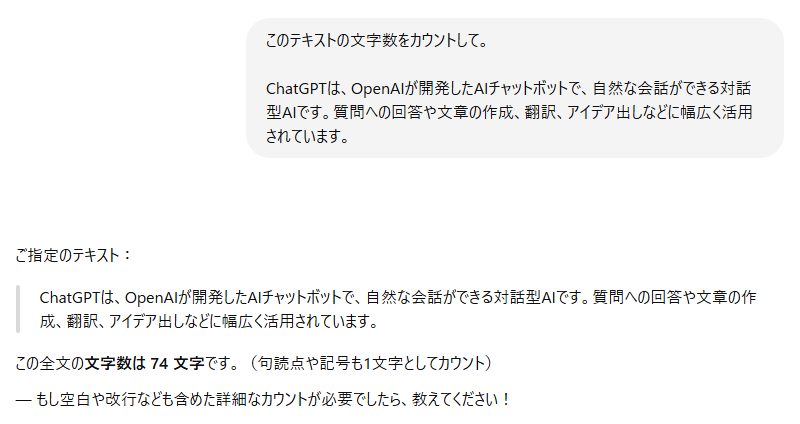
ChatGPT に「このテキストの文字数をカウントして」と依頼したところ、返ってきた答えは 74文字 でした。
自分の手元で数えた結果と異なるため、「どこかで数え方に差があるのだろうか?」と疑問が浮かびました。ただこの時点では、まだ原因は分かりませんでした。
「Pythonでカウントして」も試してみた
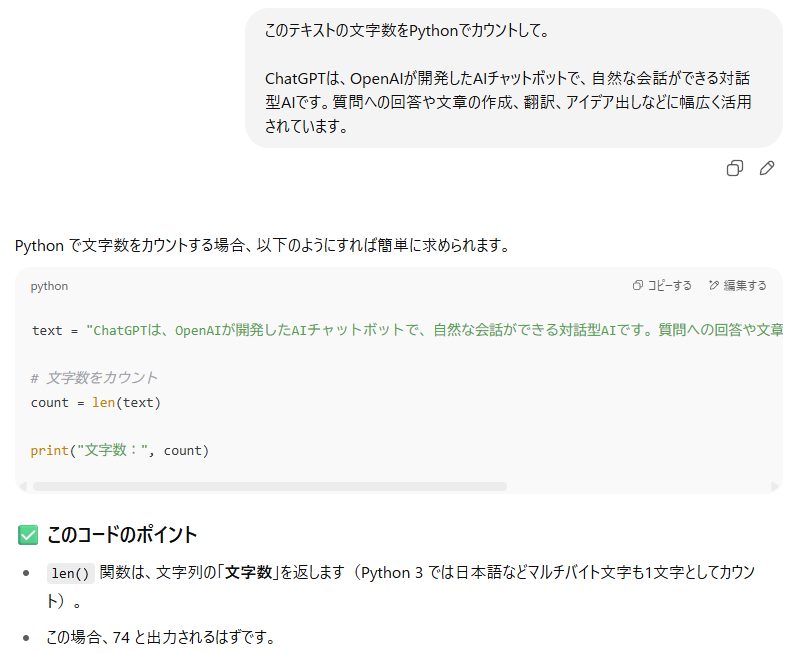
次に、「Python を使えば正確にカウントできるのでは」と考え、「このテキストの文字数を Python でカウントして」と依頼しました。
ChatGPT は len() 関数を使った Python のコードを提示し、一見すると正しくカウントできそうに思えました。
しかし、実行結果として返ってきたのは先ほどと同じ 74文字 でした。
これで、単にカウント方法を変更しただけでは解決しないことが分かりました。
len() 関数でも 74 文字と表示されたコラム:ChatGPTはなぜ「数えたつもり」になるのか
この時点ではまだ確信が持てませんでしたが、後から調べてみると、ChatGPT が「文字数を数える」と言って返してくる内容は、実際には以下のような 近似的な処理 に基づいていることが多いようです。
トークン単位で概算している
ChatGPT は文字数ではなく、トークン と呼ばれる単位でテキストを処理しています。日本語ではおおよそ 1 文字 1 トークンに近いですが、語句のまとまりや頻出パターンはまとめて処理されることがあり、必ずしも一致しません。また英語は日本語に比べて、単語や接頭辞・接尾辞など、細かい単位で分割される傾向があります。
経験則で「このくらい」と見積もる
学習データや過去の出力パターンに基づき、「200文字ならこれぐらいの内容だろう」といった 感覚的な出力 になることもあります。そのため、文章構成や語彙によって、実際の文字数は前後する場合があります。
len() も「実行せず、出力だけ」
「len() で計算した」と説明しながらも、実際にはコードを実行せず、計算結果っぽい数字だけを出力している こともあります。つまり、“それっぽい回答”に過ぎない場合がある、ということです。
ChatGPT に「正確にカウントする方法」を尋ねた
そこで ChatGPT に「正しい文字数をカウントするには、どう指示すればよいか?」と尋ね、適切なプロンプトを作ってもらうことにしました。
その回答の中に、次のような一文がありました。
コード実行モード(Advanced Data Analysis)を使ってカウントすること
この時、私は初めて「Advanced Data Analysis」という機能の存在を知りました。
Advanced Data Analysis を使ってみた
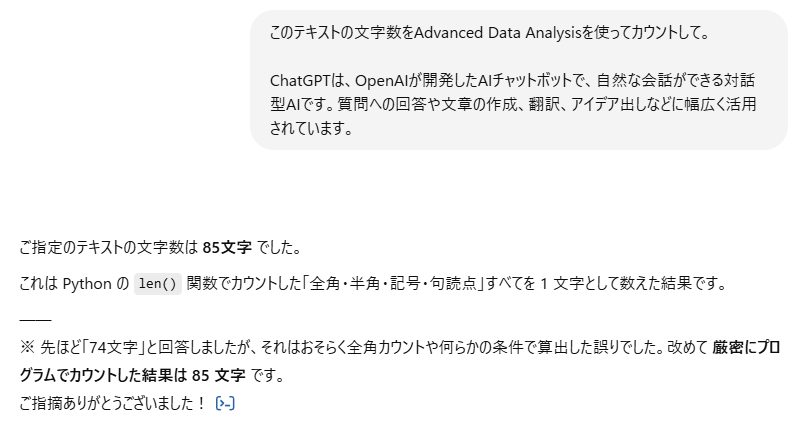
提案に従い、「Advanced Data Analysis を使用して文字数をカウントして」と依頼してみたところ、今度は 85文字 という、手元で数えた結果と一致する答えが返ってきました。
ようやく正しい結果を得ることができ、ChatGPT が 実際にデータ処理を行った結果 を返してくれたことがわかりました。
Advanced Data Analysis(旧 Code Interpreter)とは?
この「Advanced Data Analysis(高度なデータ分析)」は、ChatGPT が 実際に Python のコードを実行してデータ処理する 機能です。
主な用途
- 文字列処理(カウント・置換など)
- 表データの集計や計算
- グラフ作成や統計処理
- ファイル操作 など
メリット
- 単なる「知識ベースの回答」ではなく、実際の計算結果を返してくれる
- 回答が推測や概算ではなく、確実なデータ処理の結果に基づいている
今回のケースでも、文章を見て「だいたいこのくらい」と判断するのではなく、Python の len() 関数でカウントした正確な文字数 が返ってきた、というわけです。
Advanced Data Analysis は無料でも利用できる?
この Advanced Data Analysis は、以前は 有料プラン限定 の機能でした。
しかし 2025年7月時点では、無料プランでも利用できるようになっています。
ただし、無料プランでは以下のような制限があるようです:
- 処理回数の制限
- 負荷の高い処理や大規模なデータセットには非対応
もしこれらの制限を超えて本格的に活用したい場合は、有料プラン(Plus / Team / Enterprise など)への切り替え が必要になるとのことです。
まとめ:試して気づいた、モードによる違い
今回の体験から感じたのは、ChatGPT の「通常の会話モード」と「データ処理モード」では、回答の根拠や精度が異なる ということです。
文字数のような明確な数値を扱う場合は、Advanced Data Analysis を使ってデータとして処理させる ことで、より正確な結果を得られることがわかりました。
ChatGPT はただ会話するだけでなく、こうした 実行環境を活用することで、さらに正確な回答が得られる のだと実感しました。
皆さんもぜひ試してみてください。

